ML2SQL
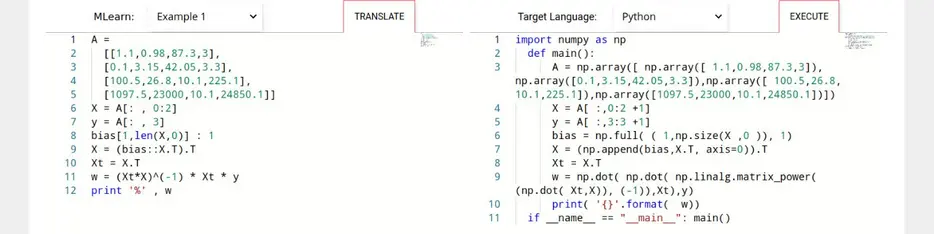
This demonstration presents a machine learning language MLearn that allows declarative programming of machine learning tasks similarly to SQL. Our demonstrated machine learning language is independent of the underlying platform and can be translated into SQL and Python as target platforms. As modern hardware allows database systems to perform more computational intense tasks than just retrieving data, we introduce the ML2SQL compiler to translate machine learning tasks into stored procedures intended to run inside database servers running PostgreSQL or HyPer. We therefore extend both database systems by a gradient descent optimiser and tensor algebra. In our evaluation section, we illustrate the claim of running machine learning tasks independently of the target platform by comparing the run-time of three in MLearn specified tasks on two different database systems as well as in Python.
We infer potentials for database systems on optimising tensor data types, whereas database systems show competitive performance when performing gradient descent.
Maximilian E. Schüle, Matthias Bungeroth, Alfons Kemper, Stephan Günnemann, Thomas Neumann
MLearn: A Declarative Machine Learning Language for Database Systems
3rd Workshop on Data Management for End-to-End Machine Learning (DEEM@SIGMOD 2019)
Maximilian E. Schüle, Matthias Bungeroth, Dimitri Vorona, Alfons Kemper, Stephan Günnemann, Thomas Neumann
ML2SQL - Compiling a Declarative Machine Learning Language to SQL and Python
22nd International Conference on Extending Database Technology (EDBT 2019)
SQL Lambda Functions
As part of the code-generating database system HyPer, SQL lambda functions allow user-defined metrics to be injected into data mining operators during compile time. Since version 11, PostgreSQL has supported just-in-time compilation with LLVM for expression evaluation. This enables the concept of SQL lambda functions to be transferred to this open-source database system. In this study, we extend PostgreSQL by adding two subquery types for lambda expressions that either pre-materialise the result or return a cursor to request tuples. We demonstrate the usage of these subquery types in conjunction with dedicated table functions for data mining algorithms such as PageRank, k-Means clustering and labelling. Furthermore, we allow four levels of optimisation for query execution, ranging from interpreted function calls to just-in-time-compiled execution. The latter---with some adjustments to the PostgreSQL's execution engine---transforms our lambda functions into real user-injected code. In our evaluation with the LDBC social network benchmark for PageRank and the Chicago taxi data set for clustering, optimised lambda functions achieved comparable performance to hard-coded implementations and HyPer's data mining algorithms.
Maximilian E. Schüle, Dimitri Vorona, Linnea Passing, Harald Lang, Alfons Kemper, Stephan Günnemann, Thomas Neumann
The Power of SQL Lambda Functions[Poster][Webinterface]
22nd International Conference on Extending Database Technology (EDBT 2019)
Maximilian E. Schüle, Jakob Huber, Alfons Kemper, Thomas Neumann
Freedom for the SQL-Lambda: Just-in-Time-Compiling User-Injected Functions in PostgreSQL
32nd International Conference on Scientific and Statistical Database Management (SSDBM 2020)
TardisDB
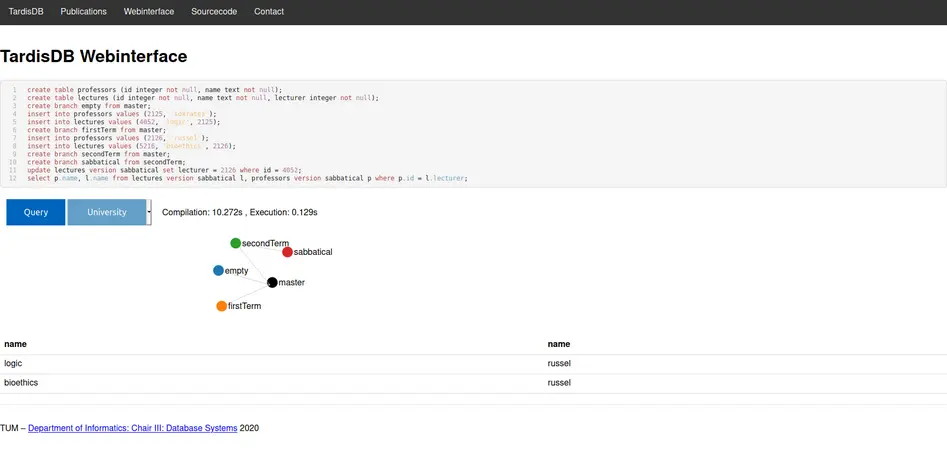
Online encyclopaedias such as Wikipedia implement their own version control above database systems to manage multiple revisions of the same page. In contrast to temporal databases that restrict each tuple's validity to a time range, a version affects multiple tuples. To overcome the need for a separate version layer, we have created TardisDB, the first database system with incorporated data versioning across multiple relations. This paper presents the interface for TardisDB with an extended SQL to manage and query data from different branches. We first give an overview of TardisDB's architecture that includes an extended table scan operator: a branch bitmap indicates a tuple's affiliation to a branch and a chain of tuples tracks the different versions. This is the first database system that combines chains for multiversion concurrency control with a bitmap for each branch to enable versioning. Afterwards, we describe our proposed SQL extension to create, query and modify tables across different, named branches.
In our demonstration setup, we allow users to interactively create and edit branches and display the lineage of each branch.
Maximilian E. Schüle, Josef Schmei?er, Thomas Blum, Alfons Kemper, Thomas Neumann
TardisDB: Extending SQL to Support Versioning[Slides][Webinterface][Video][Source Code]
ACM SIGMOD International Conference on Management of Data (SIGMOD 2021)
Lukas Karnowski, Maximilian E. Schüle, Alfons Kemper, Thomas Neumann
Umbra as a Time Machine: Adding a Versioning Type to SQL[Slides]
19th symposium of "Database systems for Business, Technology and Web" (BTW 2021)
Maximilian E. Schüle, Lukas Karnowski, Josef Schmei?er, Alfons Kemper, Thomas Neumann
Versioning in Main-Memory Database Systems: From MusaeusDB to TardisDB
31st International Conference on Scientific and Statistical Database Management (SSDBM 2019)
Automatic Differentiation

Both forward and reverse mode automatic differentiation derive a model function as used for gradient descent automatically. Reverse mode calculates all derivatives in one run, whereas forward mode requires rerunning the algorithm with respect to every variable for which the derivative is needed. To allow for in-database machine learning, we have integrated automatic differentiation as an SQL operator inside the Umbra database system. To benchmark code-generation to GPU, we implement forward as well as reverse mode automatic differentiation. The inspection of the optimised LLVM code shows that nearly the same machine code is executed after the generated LLVM code has been optimised. Thus, both modes yield similar runtimes but different compilation times.
Maximilian E. Schüle, Alfons Kemper, Thomas Neumann
NN2SQL: Let SQL Think for Neural Networks
20th symposium of "Database systems for Business, Technology and Web (BTW 2023)
Maximilian E. Schüle, Harald Lang, Maximilian Springer, Alfons Kemper, Thomas Neumann, Stephan Günnemann
Recursive SQL and GPU-support for in-database machine learning
Distributed and Parallel Databases: Scientific and Statistical Data Management in the Age of AI 2021
Maximilian E. Schüle, Alfons Kemper, Thomas Neumann
Recursive SQL for Data Mining[Video][Slides]
34th International Conference on Scientific and Statistical Database Management (SSDBM 2022)
Maximilian E. Schüle, Maximilian Springer, Alfons Kemper, Thomas Neumann
LLVM Code Optimisation for Automatic Differentiation[Slides]
6th Workshop on Data Management for End-to-End Machine Learning (DEEM@SIGMOD 2022)
Maximilian E. Schüle, Tobias G?tz, Alfons Kemper, Thomas Neumann
ArrayQL for Linear Algebra within Umbra
33rd International Conference on Scientific and Statistical Database Management (SSDBM 2021)
Maximilian E. Schüle, Harald Lang, Maximilian Springer, Alfons Kemper, Thomas Neumann, Stephan Günnemann
In-Database Machine Learning with SQL on GPUs[Video][Slides]
33rd International Conference on Scientific and Statistical Database Management (SSDBM 2021)
Maximilian E. Schüle, Frédéric Simonis, Thomas Heyenbrock, Alfons Kemper, Stephan Günnemann, Thomas Neumann
In-Database Machine Learning: Gradient Descent and Tensor Algebra for Main Memory Database Systems[BibTeX][Poster][Slides]
18th symposium of "Database systems for Business, Technology and Web" (BTW 2019)